新鲜 / 健康 / 便利 / 快速 / 放心

类似于生产调度中的job shop问题,背包问题,tsp等np hard问题,有没有用深度学习的方式求解?我理解深度学习最原始的训练方法是梯度下降,但是大规模的组合优化问题都很难用数学描述,适应度地貌是离散点组成的坑坑洼洼的曲面。只能用启发式或者元启发式搜索,例如遗传,禁忌,粒子群等。但是也存在问题就是评价解速度太慢,我的经验是95%浪费在解码阶段,强化学习可以解决这个评价速度慢的问题吗?两个问题,请各位不吝指教,谢谢!
工作相关,所以对强化学习在组合优化方面有所研究。以下是相关的一些论文和github链接:
这篇是之后几篇的基础了吧,提出了pointer decoding的方式,求解TSP问题。
2. Neural combinatorial optimization with reinforcement learning:
https://arxiv.org/pdf/1611.09940.pdf代码实现参考:
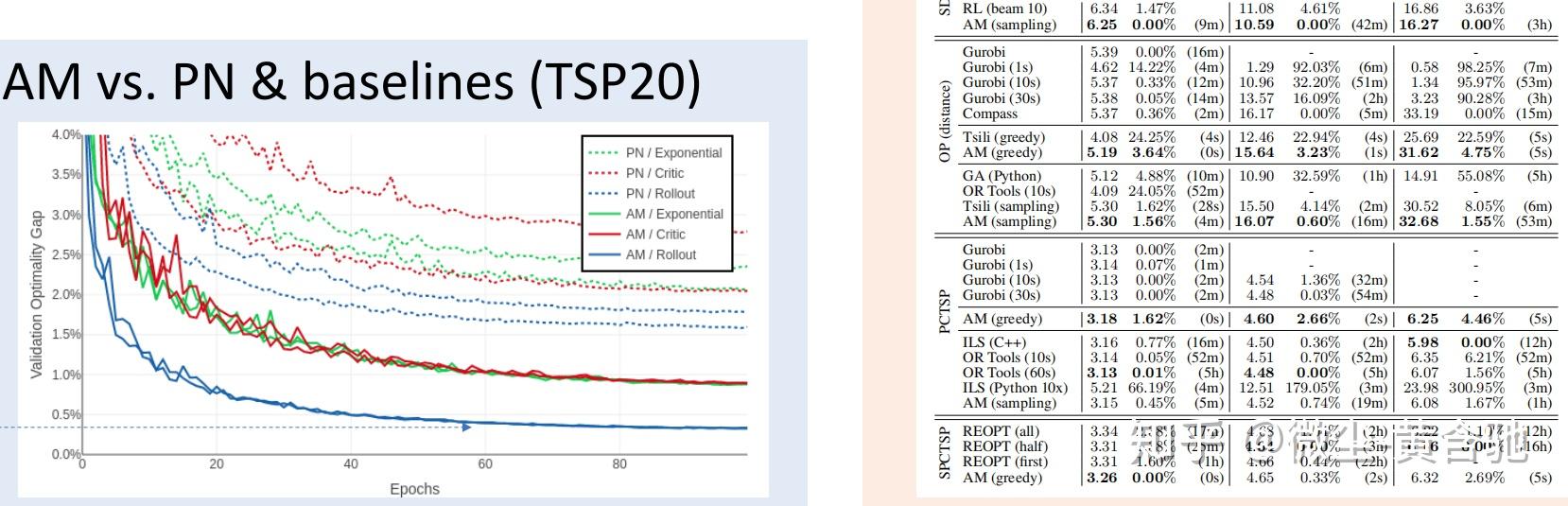
https://github.com/pemami4911/neural-combinatorial-rl-pytorchhiggsfield/np-hard-deep-reinforcement-learningGoogle的这篇借用pointer network加上attention mechanism,用policy gradient优化,actor-critic训练。也求解了knapsack的问题。我实现的经验来说,moving average的效果比actor-critic训练更稳定一些,actor-critic有时候会爆掉。这篇应该是被ICLR拒了。
3. Reinforcement learning for solving vehicle routing problem:
https://arxiv.org/pdf/1802.04240.pdf代码实现参考:
mveres01/pytorch-drl4vrpLeigh发的这篇的基础是前面两篇,简化的pointer network的encoding过程,直接进行embedding。主要延伸到解VRP问题,也解了TSP问题,和之前的进行了对比。
4. Learning Combinatorial Optimization Algorithms over Graphs:
Learning Combinatorial Optimization Algorithms over Graphs作者的github:
Hanjun-Dai/graph_comb_opt这篇先graph embedding的思路(structure to vector),然后Reinforce to train。从small scale training transfer到large scale表现也还不错。作者是用c++写的,后来也发了pytorch版本,但是底层还是c++。我用pytorch实现了一下,但是原文中graph embedding也是属于训练的部分,在pytorch中backward会有问题。如果有深入了解的,可以交流一下。
5. Attention: Learn to solve routing problems!
https://openreview.net/pdf?id=ByxBFsRqYm原作者的github:
wouterkool/attention-tspICLR2019的一篇。这篇的整体思路也是encoder(一个复杂的attention)+decoder。这篇包罗万象,解了各种tsp和vrp变种,还有其它,也和pointer network做了对比 。我初略地看了一下,没有细看。
6. 仓储优化中的beer game问题:
https://arxiv.org/pdf/1708.05924.pdf用deep reinforcement learning的方法,分别对4个agent(manufacturing, distributor, warehouse, retailer) 建立network,然后用一个feedback scheme去让agent向一个目标前进。
综上,TSP和VRP问题主要的思路是encoder + decoder。encoder有很多方法,graph embedding, attention, glimpse, multi-head等,decoder也同样。但是训练好的model的robustness还有待考验。有相关研究的同学,可以一起交流一下。个人github:
jingw2 - Overview2017年阿里巴巴就有一篇用深度强化学习求解3维装箱问题的论文。深度学习和强化学习的兴起让我们会思考一个大一点的命题:单纯的采用基于Search的传统数学优化方法可能有着局限性,基于深度学习和强化学习的Learning to Search方法是否能帮助我们更好的寻找最优解呢?
一. 深度学习和强化学习求解组合优化问题思路简介
回顾神经网络发展历史,早在1982年就有采用Hopfield神经网络来求解TSP问题(旅行商问题)。Hopfield神经网络是一种递归神经网络,从输出到输入均有反馈连接,每一个神经元跟所有其他神经元相互连接,又称为全互联网络。对Hopfield神经网络的研究更是引领了八十年代人工智能研究的复兴。
最近2-3年来在人工智能顶级会议NIPS, ICML 上都已经有不少相关的论文了,感兴趣可以多去关注,我们这里先从宏观上说一下深度学习和强化学习如何帮助求解组合优化问题。
1. 组合优化的序列决策可以由深度学习或强化学习来替代
组合优化问题大多数情况下都是涉及到决策顺序,即序列的决策问题,例如对于TSP问题就是决定以什么顺序访问每一个城市,例如对于Job shop问题(加工车间调度问题)就是决定以什么顺序在机器上加工工件。而深度神经网络里边的递归神经网络恰好可以完成从一个序列到另一个序列的映射问题,因此可以借用递归神经网络来直接求解组合优化问题完全是一种可行的方案。另外一套方案就是采用强化学习,强化学习天生就是做序列决策用的,那么组合优化问题里边的序列决策问题完全也可以用强化学习来直接求解,其难点是怎么定义state, reward。
2. 求解组合优化的经典算法可以由强化学习帮助指导算法策略
分支定界算法是一种最常见的求解整数规划问题的方法。关于分支定界算法可以参考这篇:【学界】混合整数规划/离散优化的精确算法--分支定界法及优化求解器 https://mp.weixin.qq.com/s/Ktb0Sf4lLT1WEjQRwhXwOg。分支定界算法的效率取决于从哪个变量 branch 和 node selection两个因素,如果branch 和 node selection的策略比较好,那么分支定界算法可以很快的剪枝或者可以很快的得到比较好的界,就可以大大提升分支定界算法的效率。目前对于 branch 和 node selection的策略还没有公认的太好的方法。传统的方法基本上都是一些简单的启发式规则,那么强化学习可以帮助我们有效的给出一个 branch 和 node selection的策略。这样的一种策略也被称为Learning to search,有别于以往单纯的基于Search的传统优化方法,Learning to search还是在优化过程中引入学习的概念帮助更加有效的搜索最优解。
2014年在NIPS会议上,文章[5]是比较早的一个用机器学习算法来学习分支定界算法里边的 branch 和 node selection的策略的。到了2017年,加拿大蒙特利尔的Andrea Lodi还写了一个survey[5],里边总结了各种关于Learning to search的研究的进展情况,写得非常全面。目前这方面的研究也处于探索中,值得我们有所期待。
二. 专为组合优化求解而诞生的神经网络 -- Pointer Network 介绍
前面谈到了组合优化问题很多时候就是进行序列决策,而Pointer Network就是非常适合求解组合优化问题的一种神经网络。Pointer Network(后面简称Ptr-Net)是基于Sequence-to-Sequence网络生成的一种新的网络架构。Ptr-Net与Sequence-to-Sequence类似,都是解决从一个序列到另一个序列的映射问题,不同的是Ptr-Net针对的序列问题更加特殊:输出序列的内容与输入序列的内容完全一致,只是序列的顺序发生了改变。这种问题在实际中常见的应用就是组合优化问题,因此Ptr-Net首次建立了神经网络与组合优化问题的联系。
下面我们简单介绍一下Ptr-Net的基本原理,这里不涉及公式推导,若感兴趣,可以参看论文:https://arxiv.org/pdf/1506.03134.pdf
相信对深度学习有一定了解的同学对Sequence-to-Sequence模型并不陌生,它利用一个RNN将输入映射为一个嵌入(embedding),在利用另一个RNN将嵌入映射成为输出,这两个RNN我们分别称之为encoding和decoding。然而在实际这种结构忽略了一个十分重要的问题:输出序列每个元素都与输入序列的一个或多个元素存在某种联系。注意力机制(Attention Machanisim)正是为了解决这一问题而被提出,在计算输出序列时,它会通过某种方式得到该输出序列某一个位置的元素与输入序列每一个位置关联的权重,然后将输入序列与该权重以一定的方式组合来影响输出。Ptr-Net正是利用了注意力机制解决了对输入序列排序的问题。通过注意力机制,可以计算出当前输出与输入序列关系最大的元素,那么我们就将输入序列的元素作为该输出元素,每一个输出元素都像有一个指针一样指向输入元素,Pointer Network因此得名。需要注意的是,每个输入元素只能被一个输出元素所指,这样就避免了输入元素的重复出现,下图给出Ptr-Net的基本结构图:
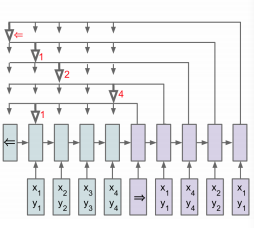
Google Brain曾经用pointer network加上attention mechanism,来求解TSP问题和背包问题,附上论文和代码实现:
https://arxiv.org/pdf/1611.09940.pdf?
代码实现参考:
https://github.com/pemami4911/neural-combinatorial-rl-pytorch?
higgsfield/np-hard-deep-reinforcement-learning?
三.总结
除了上面提到的其实还有GNN(图神经网络)求解组合优化问题也是非常有趣的话题。这里无法一一对每一种方法进行详细的介绍。关于深度学习和强化学习求解组合优化问题的研究目前还处于一个探索阶段,必须承认的是目前的这些研究思路比较新奇,交叉学科非常好玩,但是就当下的情况来看短期内难以撼动传统数学优化和组合优化的方法。
参考文献:
[1]Hu H, Zhang X, Yan X, et al. Solving a new 3d bin packing problem with deep reinforcement learning method[J]. arXiv preprint arXiv:1708.05930, 2017.
[2]Khalil E B. Machine Learning for Integer Programming[C]//IJCAI. 2016: 4004-4005.
[3]He H, Daume III H, Eisner J M. Learning to search in branch and bound algorithms[C]//Advances in neural information processing systems. 2014: 3293-3301.
[4]Comments on: On learning and branching: a survey
[5]Lodi A, Zarpellon G. On learning and branching: a survey[J]. TOP, 2017: 1-30.
[6]Dai H, Khalil E B, Zhang Y, et al. Learning Combinatorial Optimization Algorithms over Graphs[J]. arXiv preprint arXiv:1704.01665, 2017.
运用深度强化学习求解组合优化问题是目前非常火热的一个研究方向,Bengio 有一篇综述回顾了深度强化学习求解组合优化问题的各个研究方向的发展情况,论文题目为“Machine Learning for Combinatorial Optimization: a Methodological Tour d’Horizon”。
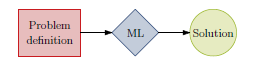
在这篇文章中,他将研究方向分为了三类: end-to-end learning(如下图一):
Learning meaningful properties of optimization problems(如下图二):
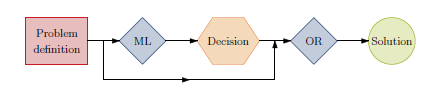
Machine learning alongside optimization algorithms(如下图三):
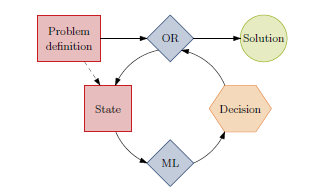
由于end-to-end learning 更能体现完全的人工智能,因此下面对利用深度强化学习求解组合优化问题的end-to-end类型的方法进行回顾。
Vinyals 2015: Pointer Network + Deep Learning
2015年, Vinyals等人基于Seq2Seq模型,提出了Pointer Network 网络,用于求解TSP问题,但是Vinyals的方法还是基于监督学习,需要样例的标签来辅助训练。众所知周,组合优化问题的标签很难获取,尤其是当问题规模较大的时候,因此该方法也存在一定的局限性。
Bello 2016: Pointer Network + Reinforcement Learning
2016年,Bello在Vinyals的pointer network基础上,提出利用强化学习来训练网络,解决了需要依赖标签的问题。在该研究中,利用的是基于actor-critic的强化学习方法。
Nazari 2018: Attention model + Reinforcement Learning
2019年, Nazari认为Bello网络中seq2seq部分的Encoder部分其实并不需要考虑输入点的顺序,因此将该部分换成了一个一维卷积,从而提出了自己的注意力机制网络,并且利用强化学习进行训练。他的结果在中等规模的VRP问题上比Google OR-Tools效果更好。
Kool 2019: Transformer + Reinforcement Learning
2019年,Kool基于在NLP中效果不错的transformer网络,提出了自己的网络来求解VRP和TSP,并且用带有self critic的强化学习来求解。最终结果比以上方法中结果都更好。
查看我的更多相关回答:
溪亭日暮:汇编 | 我的AI 技术回答1.以下解读尽量避开深度学习或强化学习在组合优化方面有哪些应用?中的论文~~~~ 2.(好想研究ml/rl+组合优化的小伙伴赶紧冒出来,把积极的拉个群好好讨论呀,这块要做出新意和效果来太难了哈哈哈,如果过期了就加我微信jjnuxjp5x,我拉您入群哈~目前群里聊得火热呀。btw,欢迎大家帮忙宣传,感激不尽我会尽力为社区做贡献的!)
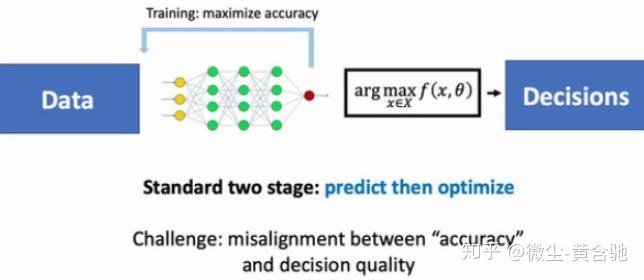
我们都知道Bengio老爷子在相关综述中提到rl+组合优化的挑战是解的可行性、建模难(如在组合优化中处理图形数据难)、scale到大问题难、数据生成难。
而,dl+组合优化难点则是:
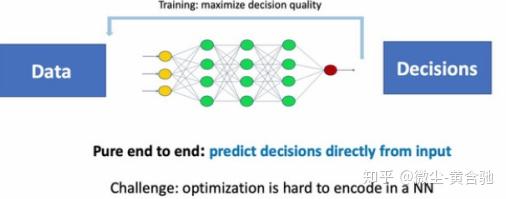
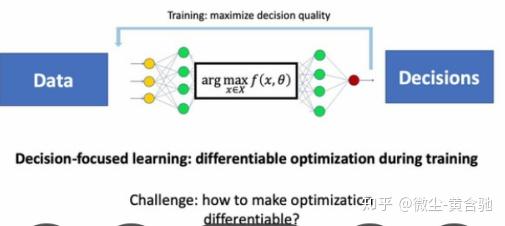
如果我们能对问题relax+differentiate,则后续解决起来轻松很多,但,
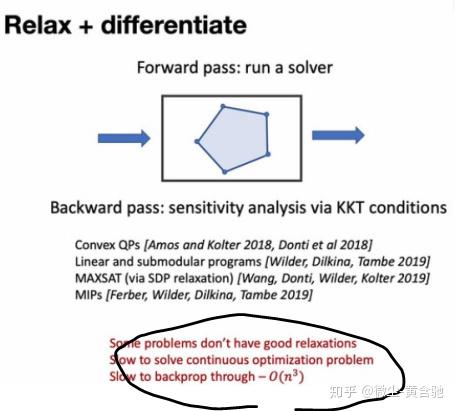
https://slideslive.com/38923998/graph-representation-learning-for-optimization-on-graphs中讲者的建议:

graph learning+graph optimization

在这项工作中,我们将较简单的问题实例化为k均值聚类的可微分形式。
因为图神经网络将节点嵌入到连续空间中,使我们得以通过在连续嵌入空间中优化来达到对离散图近似优化的目的,所以clustering is motivated。 然后,我们将 cluster assignments解释为离散问题的解。 我们针对两类优化问题实例化了该方法:需要对图形进行微分的问题(例如,社区检测或最大割),以及需要选择K个节点的子集的问题(设施位置,影响最大化,免疫接种等)。 我们并不是说聚类是适用于所有任务的正确算法结构,但足以解决本文所述的许多问题。
简言之,我们做了三个贡献。 首先,我们介绍一个用于集成图学习和优化的通用框架,并以连续空间中的更简单优化问题作为更复杂离散问题的代理。 其次,我们展示了如何通过集群层进行微分,从而将其用于深度学习系统。 第三,我们展示了在两个阶段的基线以及一系列示例域上端到端方法的实验性改进。


下图是这篇paper的海报节选。




找到与最优解的tight bounds是解决离散优化问题的关键要素之一。 在过去的十年中,决策图(DD)为获取上限和下限带来了新视角,该上限和下限可能比经典的约束机制(如线性松弛)好得多。 众所周知,通过这种灵活的边界方法获得的边界质量高度依赖于为构建图表而选择的变量的排序,而找到优化标准度量的排序是一个难题。 在本文件中,我们提出了一种基于深度强化学习的创新且通用的方法,该方法用于获得有序的命令,以收紧使用宽松和受限DD所获的界限。 我们将该方法应用于最大独立套问题和最大割问题。 合成实例的实验结果表明,通过实现更严格的目标函数界,深度强化学习方法通常胜过已知实例分布时文献中常用的排序方法。 就“我们”所知,这是第一篇将机器学习应用于直接证明通过通用约束机制获得组合优化问题的松弛边界的论文, 它为different domains that utilize DDs as constraint programming, planning or verification of systems提供了新视角、新方向。
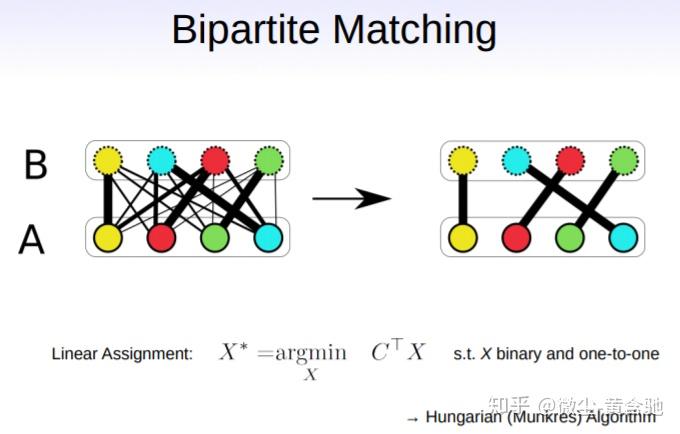
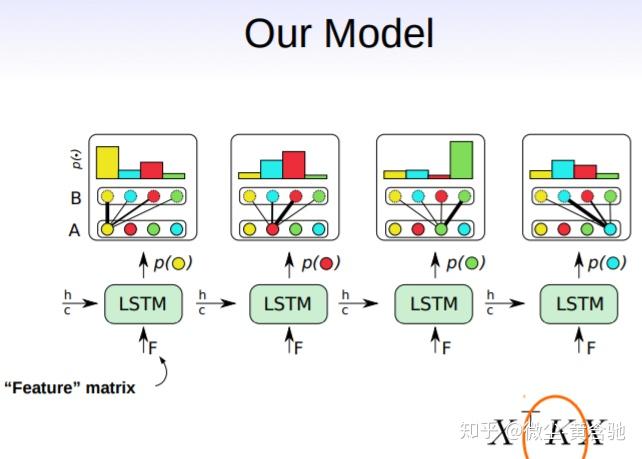
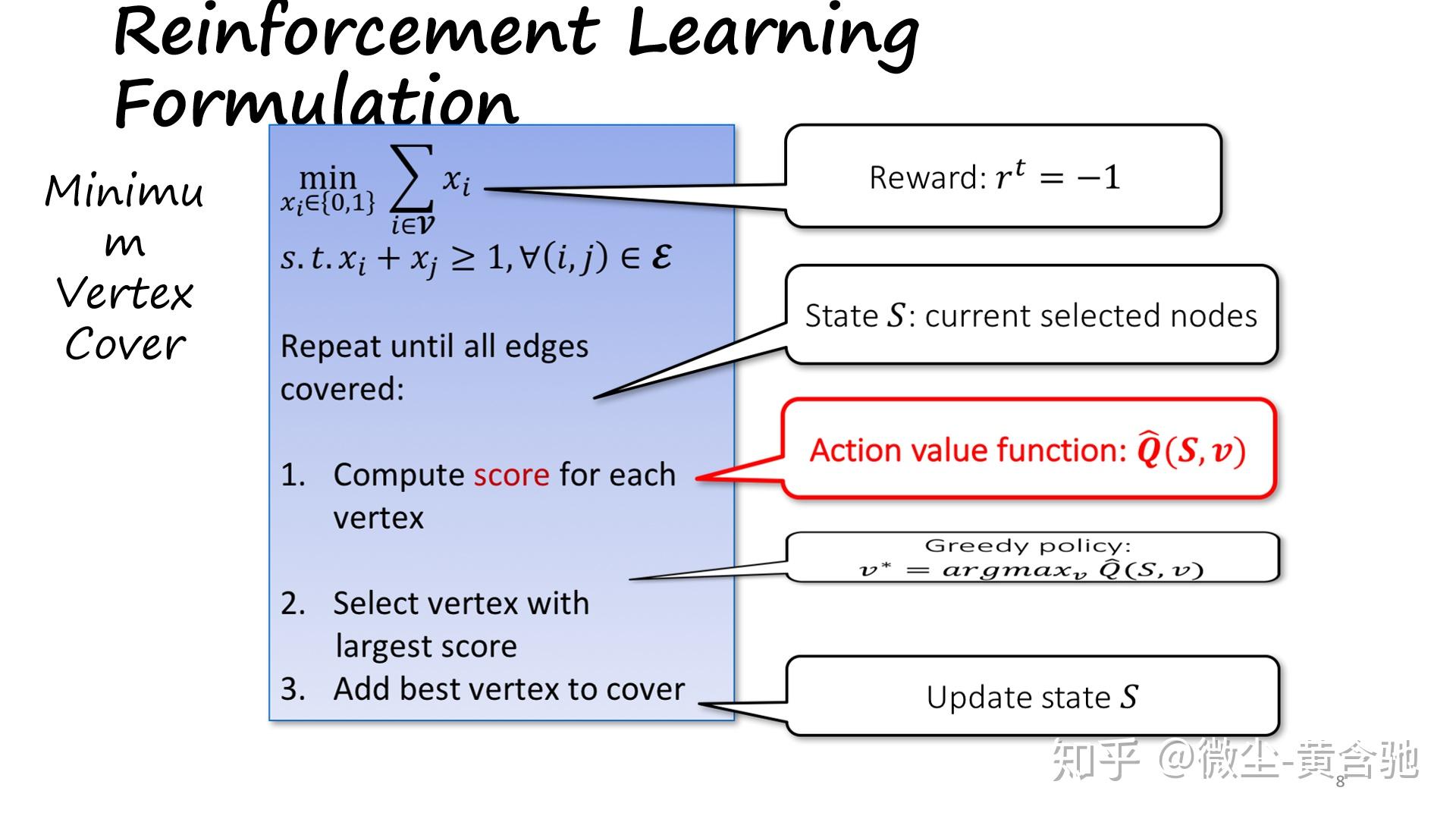
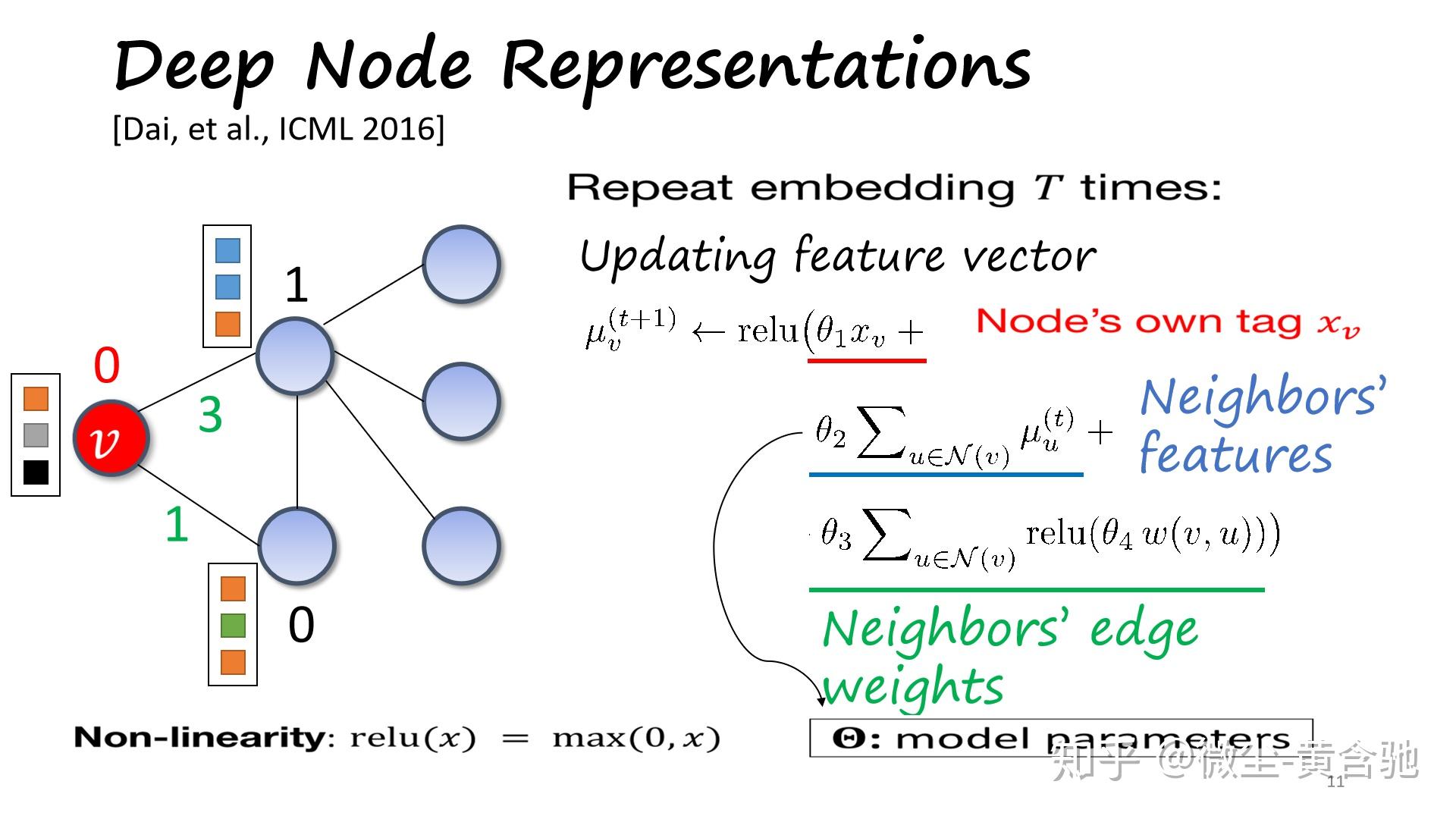
Ptr-Net无法解决点匹配问题,因为它没有充分利用两个点集间的对应关系。我们提出了多指针网络,它从多标签分类中汲取idea,使用sigmoid函数代替Ptr-Net的softmax函数,更能体现点与点间的对应关系。 我们也介绍了一个框架(a unique combination of reinforcement learning and graph embedding network)来解决图形优化问题,尤其是最大割(MAXCUT)和最小顶点覆盖(MVC)问题。
slides:http://www.milanton.de/files/aaai2017/aaai2017-anton-nphard-slides.pdf



再看TSP问题!
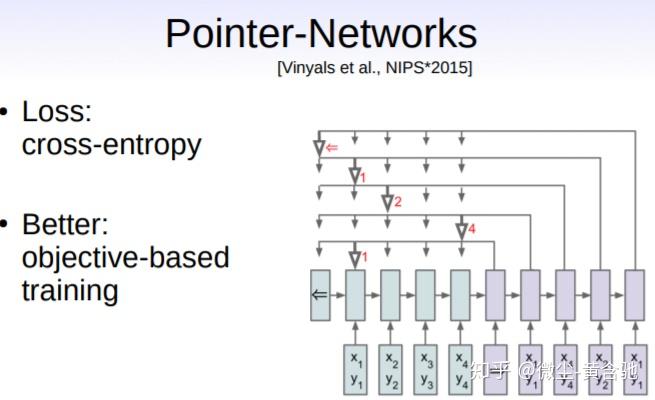
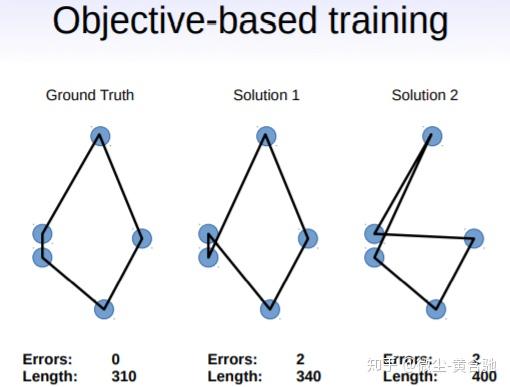
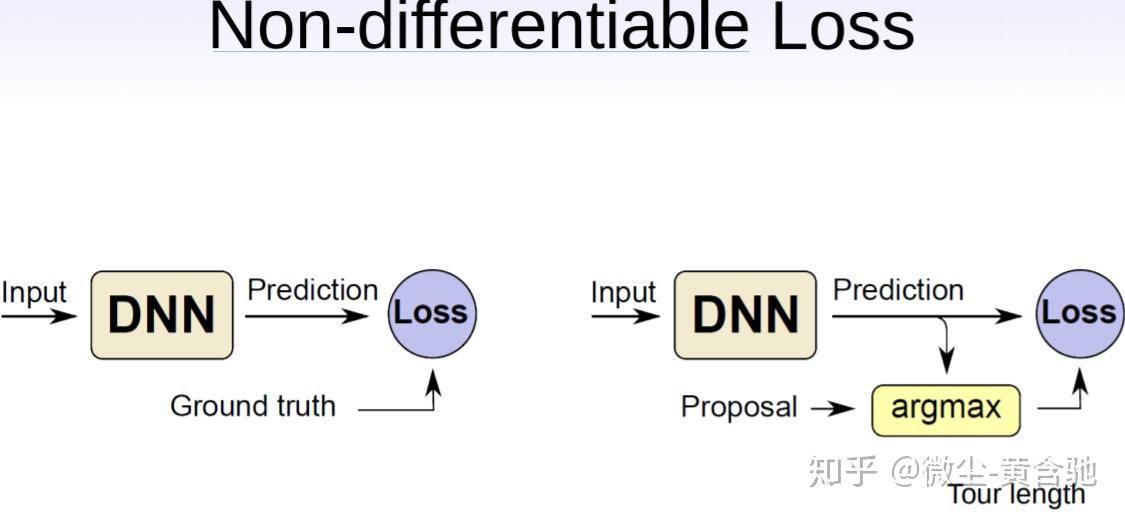
我们向传统的监督学习范例中引入了一种简单而有效的修改方法。 我们建议不要仅依靠近似的预测相似性度量(损失),而是利用真实的、不可微分的目标作为附加组件来对解进行排名,并不断改进可用的近似“ground truth”。 这使我们能在无需强监督的情况下,利用深度架构和反向传播的威力,同时又能探索解空间的很大部分。
方法:Q-learning+合适的图嵌入->效果:泛化性好、在大小图上表现都不错、能作用于许多类图(问题实例)。


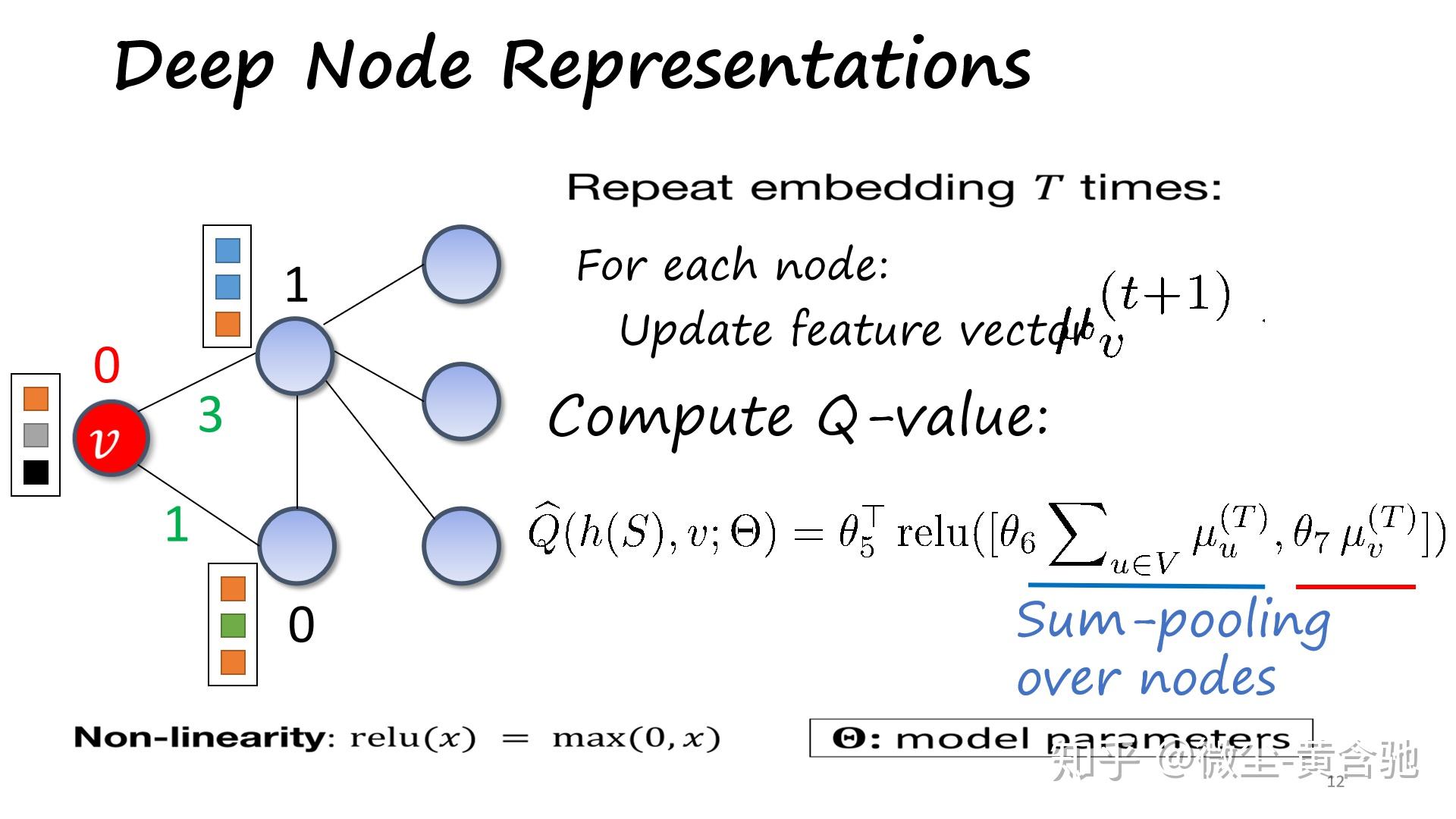
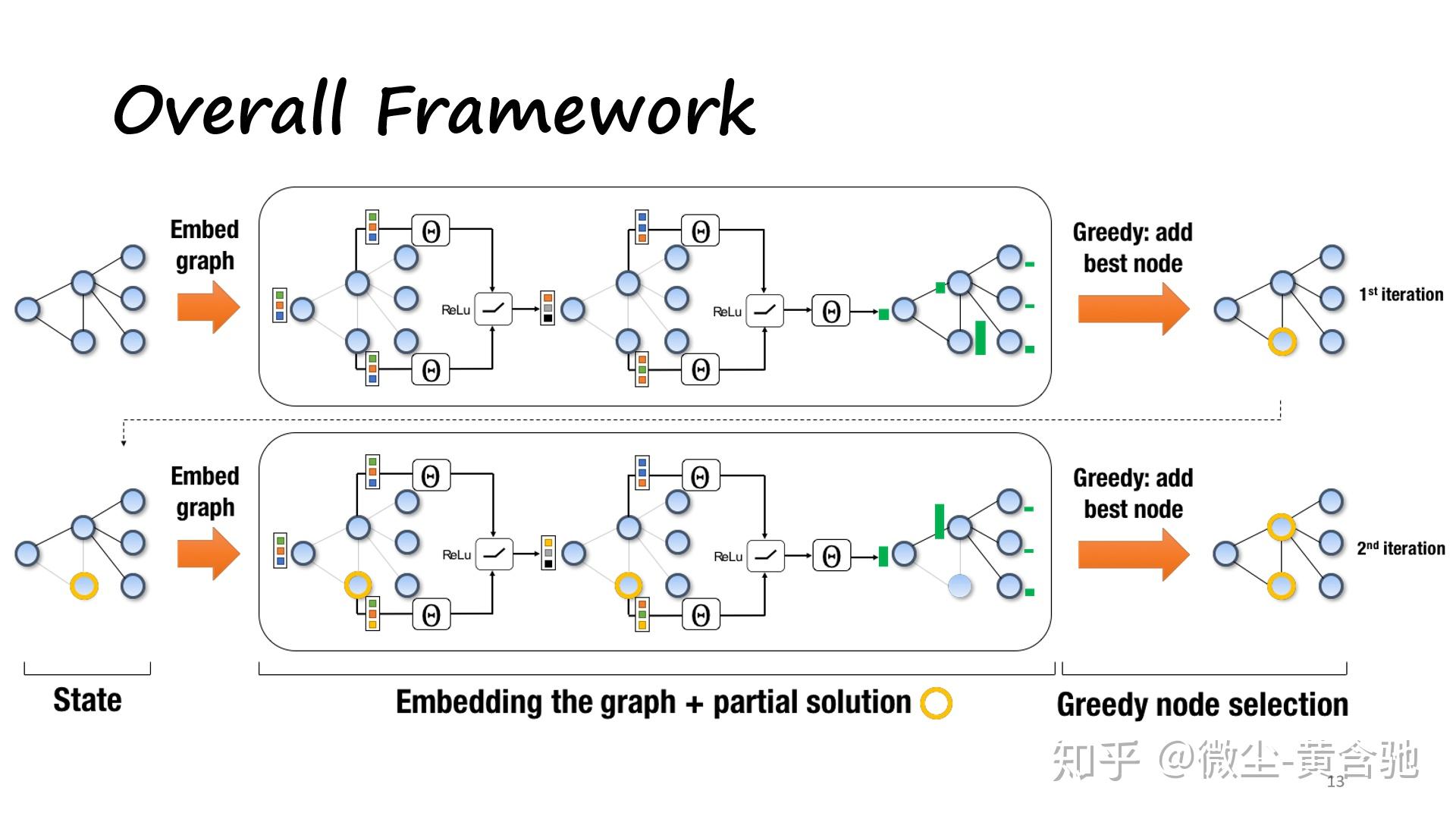

(此paper解读部分摘自https://zhuanlan.zhihu.com/p/96634714)

以2D图作为输入,Graph ConvNet模型输出一个边邻接矩阵,该矩阵表示TSP巡回中出现的边的概率,之后用波束搜索将边邻接矩阵转换为有效的巡回路线。算法是有监督训练的,且作者自称所有组件都高度并行化,
Input layer:
Node input feature:
The edge input feature:
GCN:
Node feature vector:
Edge feature vector:
MLP classififier:
损失函数:
给定 ground-truth TSP tour permutation Π,作者将tour permutation转换为邻接矩阵,其中每个元素 表示TSP tour中节点i和j之间是否存在边缘。 作者最小化了迷你批次平均的加权二进制交叉熵损失。 随着问题规模的增加,分类任务在消极类别上变得高度不平衡,这需要适当的类别权重来平衡这种影响。

波束搜索解码:
模型的输出是在tour connections的邻接矩阵上的概率热图。每个∈[0,1]^2表示节点i和j之间的边预测强度。 根据概率链规则,可以将partial TSP tour π'‘的概率表示为:
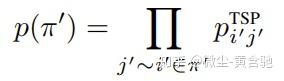
其中每个节点j’在partial tour π‘中跟随节点i’。 但是,通过argmax函数将概率热图直接转换为预测的TSP tour 的邻接矩阵表示通常会产生无效的行程,而在
中有多余或不足的边。 因此,作者在评估时采用了三种可能的搜索策略,以将概率边缘热图转换为
的有效排列。
贪婪搜索
通常,贪心算法会选择局部最优解以提供全局最优解的快速近似。 从第一个节点开始,作者根据有最高概率的边从其邻居中贪婪地选择下一个节点。 访问所有节点后,搜索终止。 作者掩盖了以前访问过的节点以构造有效的解决方案。
波束搜索
波束搜索是有限宽度的广度优先搜索[Medress et al,1977],它十分流行。波束搜索可以从生成的模型中获得用于自然语言处理任务的一组高概率序列[Wu et al,2016]。
从第一个节点开始,作者通过在节点的邻居间扩展b个最可能的边连接来探索热图。 作者迭代扩展每个阶段的前b个partial tour,直到访问了图中的所有节点。 作者遵循与贪婪搜索相同的掩蔽策略来构造有效的游览。 最终预测是波束搜索结束时,在b个完整tour中概率最高的tour(b表示波束宽度)。
波束搜索和最短tour heuristic
作者在b个完整tour中选择最短的tour作为最终tour解,而不是在波束搜索结束时选择概率最高的tour。 这种基于启发式的波束搜索可以直接与TSP的强化学习技术相提并论,后者可以从学习到的策略中抽取一组解决方案并从中选择最短的旅程作为最终解决方案[Bello等,2016; Kool等, 2019]。
其他边角料:
结合学习启发式和传统启发式
从Deudon等人[2018]的结果可以看出,将学习的启发式和传统的启发式结合起来,自回归模型可能不会产生局部最优,我们似乎可以通过使用学习算法与局部搜索启发式算法(如2-OPT)的混合方法来提高性能。 作者的非自回归模型也具有相同的观察结果。 在波束搜索中添加最短的巡回启发法会以评估时间为代价来提高性能。 当将诸如2-OPT之类的启发式方法结合到波束搜索解码中时,未来的工作将探索性能与效率之间的进一步权衡。
SL与RL的样品效率
与强化学习相比,作者的监督式训练设置具有更高的样本效率,因为SL使用有关问题的完整信息来训练模型,而RL训练则由稀疏的奖励函数来指导。要注意,每个训练图都是动态生成的,且对于RL是唯一的。 相反,监督方法从固定的一百万个实例集中随机选择并重复训练图(及其ground truth解决方案)。
与结合了深度神经网络和树搜索的强化学习算法一起使用时,两人游戏中的对抗性self-play玩法已经让人印象深刻。 诸如AlphaZero和Expert Iteration之类的算法可以学习tabula rasa,并在运行中即时生成高度有用的训练数据。 但是,self-play训练策略不能直接应用于单人游戏。 最近,一些实用的重要组合优化问题,例如旅行推销员问题和集装箱问题已被重新表述为强化学习问题,这似乎增加了使self-play游戏的收益超越两人游戏的重要性。 作者提出了排名奖励(R2)算法,该算法通过对单个agent在多个游戏中获得的奖励进行排名以创建相对性能指标来实现此目的。 将R2算法应用于二维和三维集装箱问题实例的结果表明,R2算法优于常规的Monte Carlo树搜索,启发式算法和整数规划求解器。 作者还提出了对排名奖励机制的分析,特别是对具有不同难度和不同排名阈值的问题实例的影响。
在两人游戏中使用self-play游戏时,一个有趣的agent总是会面对一个完全合适的对手,因为无论它有多弱或强,对手总是会为agent提供适当的对等水平,以便agent从中学习。 R2算法通过根据单个agent在最近游戏中的相对表现来调整单个agent的报酬,从而重现了普通单人MDP self-play的好处。 算法1给出了详细描述。

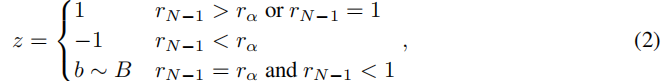
B指伯努利分布。
(此paper介绍部分摘自https://zhuanlan.zhihu.com/p/58244275)
前人的研究和想法建立的基础
与前人的区别:
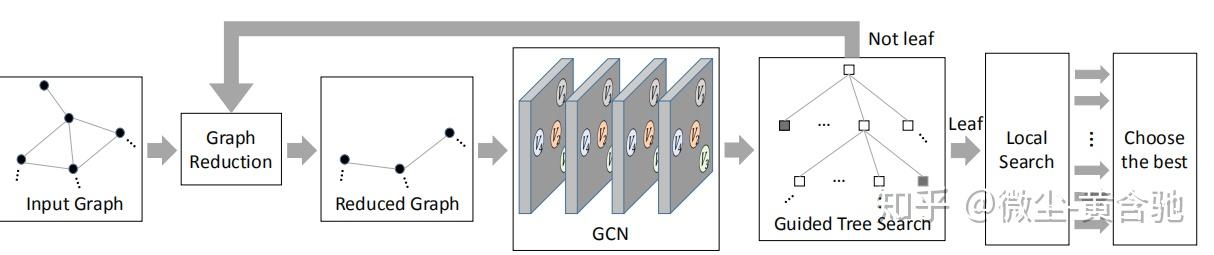
算法概述:
首先,将输入图简化为等效的较小图。 然后将其喂入图卷积网络f,该卷积网络生成多个概率图,这些图编码每个顶点处于最佳解中的可能性。 概率图用于迭代标记顶点,直到标记完所有顶点。 完整的标签对应于搜索树中的叶子。 搜索树中的内部节点表示沿途生成的不完整标签。 通过树状搜索生成的完整标签可通过快速本地搜索进行完善。最佳结果用作最终输出。
详细赞美与吐槽见https://zhuanlan.zhihu.com/p/58244275。
面对很多组合优化问题,传统求解器需要我们定义明确的结构化输入,而端到端的学习方式则没有这个严格的要求。理想情况下,我们希望能以端到端的方式将功能强大的函数逼近器(如神经网络)与有效的组合求解器进行组合, 而不做任何妥协(compromise),这正是我们这篇论文中实现了的目标,该论文获得了最高评分,并在ICLR 2020上被重点演讲。
对于以下各节,需要牢记的是,我们并不是在尝试改进求解器本身,而是要与函数逼近协同使用现有求解器。

Gradients of Blackbox Solvers
我们考虑组合求解器的方式是根据连续输入(例如图形边缘的权重)到离散输出(例如最短路径,选定的图形边缘)之间的映射来定义的。此过程中原本我们参考的损失函数是分段固定的.这意味着该函数相对于表示自变量的梯度几乎处处为0,且在跳跃点上没有定义。坦率地说,梯度原样(gradient as-is)对于最小化损失函数没有用。
迄今为止,已经有一些方法依赖于解算器对上述问题进行松弛,此过程必须就最终的最优性做出牺牲。 相比之下,我们开发了一种不影响求解器最优性的方法:通过定义原始目标函数的分段仿射插值来实现此目的,其中插值本身由超参数λ控制,如下图所示:
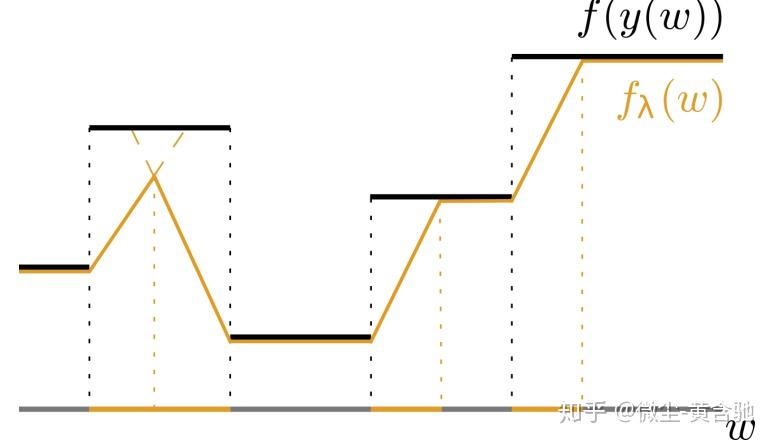
f的定义域是多维的。 超参数λ的作用是通过对求解器输入ω的扰动来移动f构成的多边形。 定义分段仿射目标的插值器g将该多边形的偏移边界连接到原始边界,如下图。 已有证明说明了后者可以提供有用的梯度。
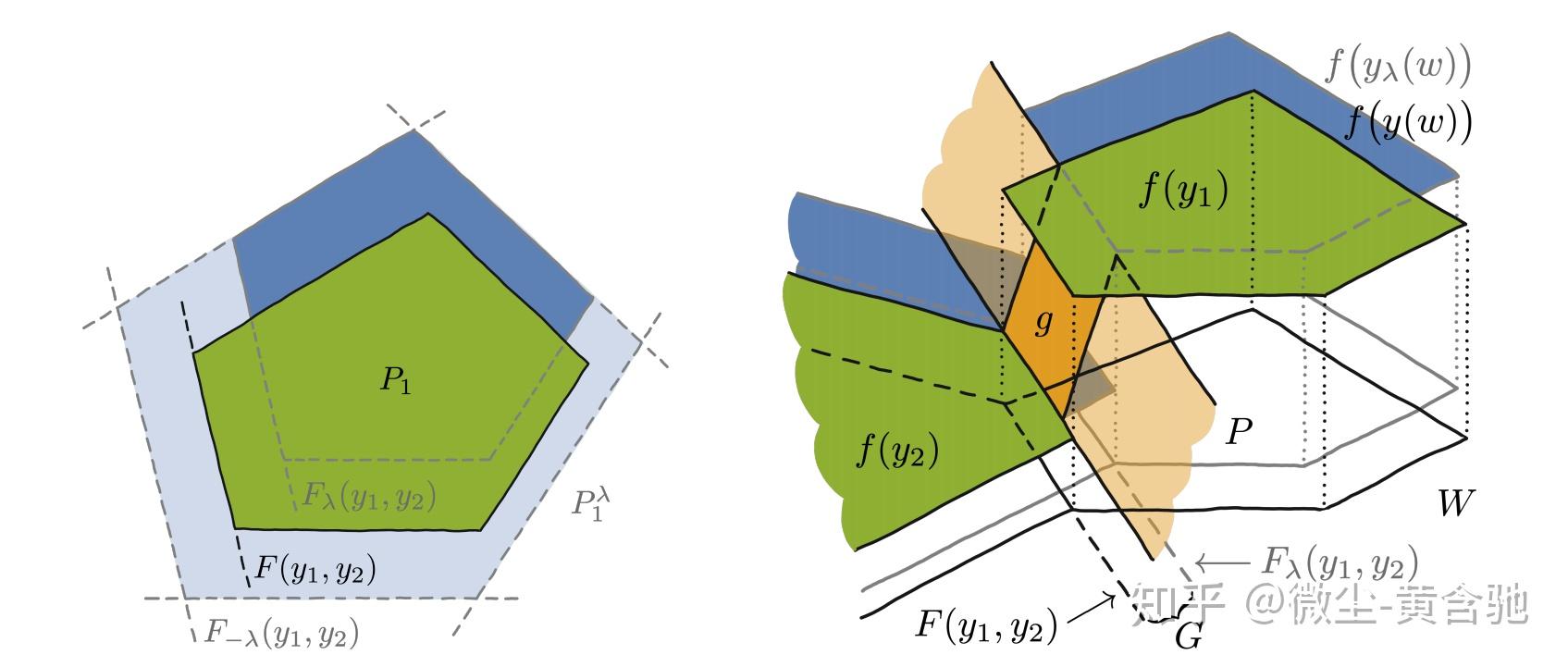
缺点:无法很好地学习约束。

将计算上的挑战转移给监督学习的Oracle。
slides http://www.cs.cmu.edu/~ckingsf/AutoAlg2019/slides/learning_to_optimize%20Yisong%20Yue.pdf 上半部分

slides http://www.cs.cmu.edu/~ckingsf/AutoAlg2019/slides/learning_to_optimize%20Yisong%20Yue.pdf 下半部分
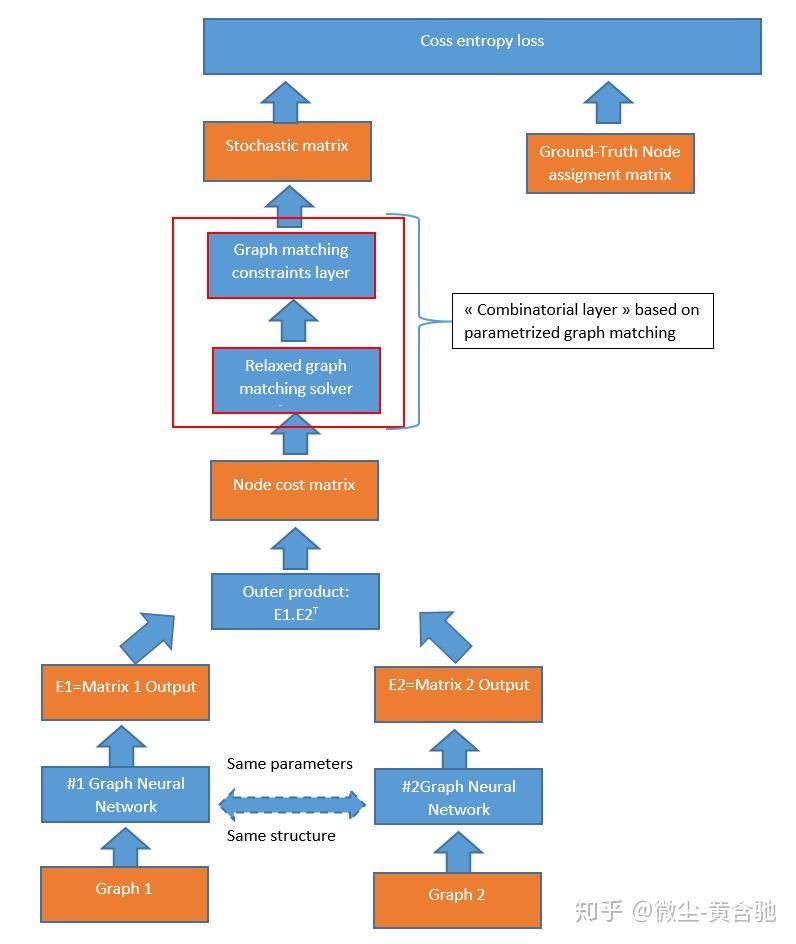
指针网络的缺点在于它假设系统是稳定不变的,而VRP问题中的需求有可能随时间变化。如果需求变化了,为了计算下一个决策点的概率,需要更新整个指针网络。为了解决这个问题,作者提出了一种比指针网络更简单的方法,即一个带有注意力机制(attention mechanism)的递归神经网络(RNN)解码器。如下图所示,左边的嵌入层将输入映射到高维的向量空间,右边的RNN解码器存储解码序列的信息。然后,RNN隐含状态和嵌入输入使用注意力机制在下一个输入上生成概率分布。 【优化】人工智能顶级会议NeurIPS 2018中优化与AI的融合
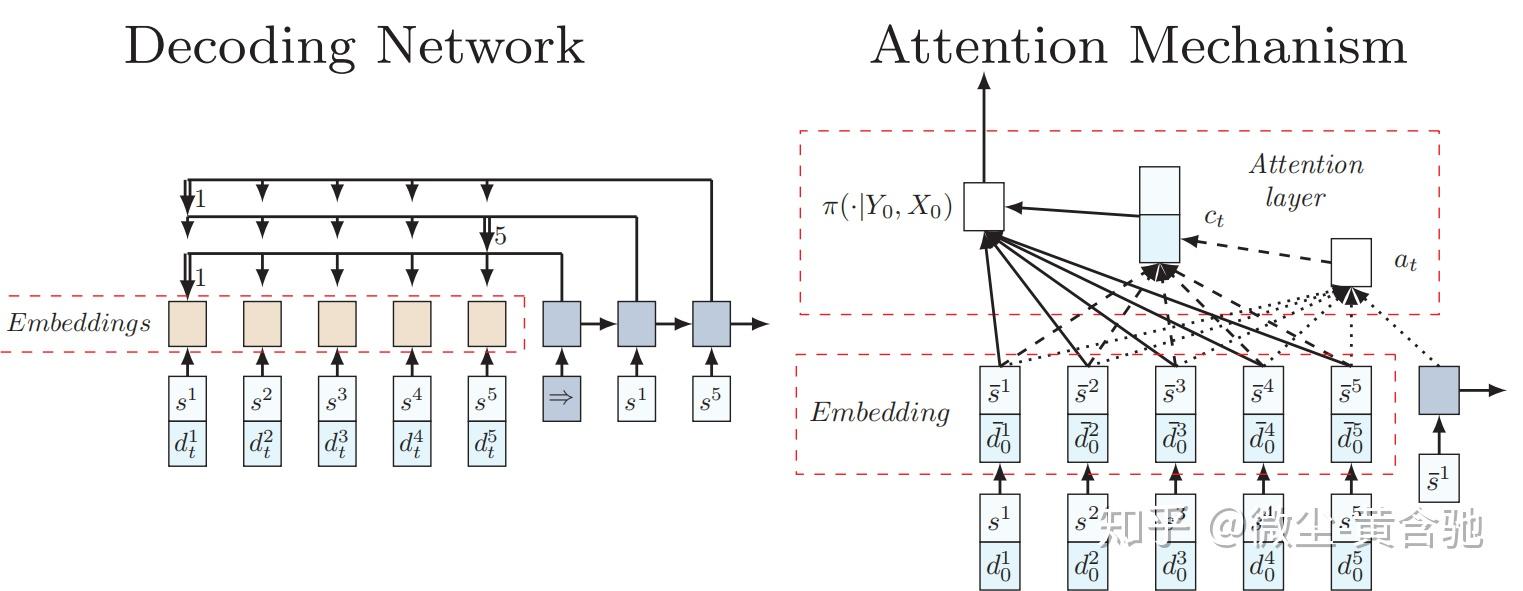
训练方法:
作者将随机的问题作为训练输入,使用著名的策略梯度方法REINFORCE。它具有两个网络:(i)预测下一个位置概率分布的actor网络(ii)评估任何问题实例回报的critic网络

这篇paper自称其框架很吸引人,因为它利用了一种自我驱动的学习过程,该过程仅需要基于生成的输出来计算奖励; 只要算法可以观察到奖励并验证生成序列的可行性,就可以学习所需的元算法。 例如,如果一个人不知道如何解决VRP,但可以计算给定解决方案的成本,则可以使用算法提供解决问题所需的“信号”。 与大多数经典的启发式方法不同,这篇paper自称其算法对问题的更改具有鲁棒性,这意味着当输入以任何方式更改时,算法都可以自动调整解决方案。
另外,使用经典启发式方法进行VRP必须重新计算整个距离矩阵,并且必须从头开始重新优化系统,这通常是不切实际的,尤其是在问题规模较大的情况下。 相反,这篇paper的算法不需要明确计算距离矩阵,这将极大提高计算效率。
这篇paper提供了强化学习和GNN representation的统一框架,用于学着去近似图上的不同问题。 该框架是第一个使用line graph for operating on either nodes or edges的框架(paper将所有图先转化为paper中定义的line graph,再进行encode、decode操作)。它通过更改奖励函数来解决不同的问题。 文章对”从小型到大型随机图“,不同类型的随机图“及”从随机图到真实世界图的泛化“进行了全面研究。 最后,文章在理论和实验中都证明了算法的线性运行时间,其运行速度比其他具有很好的最佳间隔的方法快了几个数量级。(???) 在未来工作中,作者计划学着将极大实例分解为多个部分,并求解每个子部分再合并,他们还计划研究图上的元学习组合优化问题,方法是在不同可归约问题间进行迁移学习。
关键点摘录:
1.记combinatorial optimization为CO,RL方法已通过两种不同的范例与CO集成: principal and joint learning。 在principal principal中,agent在没有优化求解器反馈的情况下直接决策。 例如在TSP问题中,可通过神经网络对agent进行参数化,该网络从一组顶点逐步构建路径,当路径达一定长度时获得奖励,该奖励用于更新agent的政策。 另一种方法是在与已经存在的求解器的联合训练中学习,它也许可改进特定问题的某些度量。 例如在MILP问题中,一种常用的方法是分枝定界法,该方法在每一步都会选择树节点上的分支规则。 这可能会对树的整体大小及算法运行时间产生重大影响。 分支规则是一种启发式方法,通常需要一些领域专业知识或超参数调整。 但是,给定已解决问题实例的数据集,参数化的RL agent可以学着去模仿节点选择的策略,从而减少算法运行时间。
2.基于价值的组合优化方法
最大切割[Barrett,2019],最小顶点覆盖率[Khalil,2017,Song ,2019],旅行推销员[Khalil,2017],集合覆盖问题[Khalil等人,2017年],最大独立集[Cappart等人,2019年]和最大公共子图[Bai等人,2020年]已被DQN“较好地”解决。
大多数工作中使用的CO任务找到最佳解决方案的常见策略是主要学习。 然而,[Cappart等人,2019]引入了另一种解决CO问题的方法:为收紧最大独立集问题和最大割问题的松弛边界,使用RL算法查找决策图(DD)中变量的最优排序。 作者还表明,对受限的DD公式使用强化学习可以找到针对上述问题的良好启发式解决方案。
以上每篇文章本质都是对Q-learning算法本身、图网络表示形式或[Barrett等,2019; Bai等,2020]进行一些特定的修改。
它们的主要区别是状态,动作和奖励表示。 对于[Khalil et al,2017],状态是p维图嵌入向量,对于时间步t处的当前节点序列,而动作是选择还没选的其他节点。,奖励是在采取某些动作a时从状态s过渡到状态s'后成本函数的差。
在[Cappart et al,2019]的工作中,状态s是一个元组(sL,sB),其中sL是变量的有序序列,而sB是在sL上构造的DD。动作是选择一个尚未选择的变量,奖励则是在将变量添加到决策图之后,根据上下限的变化来计算的,下限和上限与部分构建的DD的最长路径相关。
最后,[Bai et al,2020]的文章着重于解决最大公共子图问题,因此,为了仅使用一个网络以有意义的方式嵌入两个图形,作者构建了一个称为联合子图节点(JSNE)的新颖的图形嵌入网络。
但是,这三项工作都遇到了与[Mnih等人,2015]相同的问题,即,递归构造最佳解决方案不允许算法重新考虑导致次优解决方案的先前决策。
为了解决这些问题,[Barrett et al,2019],[Song et al,2019]的作者对通用神经Q学习方法进行了一些改动。[Song et al,2019]使用在分类领域中越来越流行的协同训练方法来构造用于CO任务的顺序策略。 文章描述了两种针对最小顶点覆盖问题的policy-learning策略:第一种策略来自[Khalil等人,2017年],即S2V with neural Q-learning。第二种是通过分支定界法解决的整数线性规划方法。 作者创建了CoPiEr算法,该算法在本质上类似于“模仿学习”,其中 the two strategies induce two policies,,对他们进行估计以找出哪种更好,然后在它们之间交换信息,最后执行更新。
ECO-DQN[Barrett et al,2019]直接针对the better state-space exploration and the scalability of the learned Q-function的任务。 为了实现这一目标,他们提出了一种不同于[Khalil et al,2017]的特殊培训框架,即,它并不是每步只学解的一部分。 相反,在每个episode开始时,它将随机实例化某些解,并允许agent“翻转”其顶点。 奖励是专门为激励探索而设计的,不会因agent执行了某些动作而惩罚agent。 相反,当agent找到一些局部最佳解决方案时(尚未探索)时,该算法可提供 的奖励。 作者使用的图嵌入网络是消息传递神经网络[Gilmer et al,2017],其权重以与前几篇文章相同的方式参数化了Q函数。
3.基于策略的组合优化方法
[Bello et al,2016]进行了将策略梯度算法应用于组合优化问题的尝试,即,使用具有学习基线的REINFORCE算法来解决TSP和背包问题。 在此,[Vinyals等,2015]提出了指针网络架构用来更方便地编码输入序列。该方案是使用解码器的指针机制根据输入的分布顺序构造的,它且类似于[Mnih等,2016]异步并行地进行训练。 此外,文章还提出了贪婪解码和采样等推理策略来构造问题的解,提出了主动搜索方法。文章称,通过主动搜索,不论从经过训练还是未经训练的模型开始,我们都能为单个测试问题实例学习到解决方案。
[Bello et al,2016]提出的方法由于其动态特性而无法直接用于解决车辆路由问题,即,一旦访问该节点,该节点的需求就为零。[Nazari等人,2018]扩展了用于解决TSP的先前方法来规避此问题,并找到用于VRP及其随机变体的解决方案。 具体而言,它们通过将LSTM单元替换为一维卷积嵌入层来简化编码器,从而使模型对于输入序列顺序不变,因此能够处理动态状态变化。 然后使用REINFORCE算法对TSP和VRP进行策略学习,使用A3C对随机VRP进行策略学习([Mnih et al,2016])。
[Deudon et al,2018]通过使用增强的编码器解码器体系结构修改[Bello et al,2016]的方法来解决TSP。 特别是,除了包含LSTM单元以外,此体系结构还完全基于关注机制,输入被编码为一个集合而不是一个序列。 此外,作者还研究了将强化学习代理提供的解决方案与2-opt启发式方法结合起来[Croes,1958]以进一步改善推理结果。
与[Deudon et al,2018]平行,[Kool et al,2018]提出了一种方法可以同时解决TSP、VRP的两个变体,定向运动问题(OP),奖品收集TSP(PCTSP)和随机PCTSP(SPCTSP)问题 。 在这项工作中,作者已经实现了类似的编码器-解码器体系结构,并使用了一个简单的 rollout baseline instead of the learned critic one。
[Hu et al,2017]以类似于[Bello et al,2016]的方式解决了另一个重要的CO问题-3D Bin Packing。 他们利用强化学习来制定策略,该策略代表了物料的最佳包装顺序。 在提供的入库商品序列的特征上训练该算法,同时通过计算包装商品的表面面积值来评估结果策略。 作者建议使用由启发式算法生成的装箱计划表面积作为基线。 为了进行推断,作者使用了贪婪解码及带有波束搜索的采样。[Duan et al,2018]的进一步工作通过结合强化和监督学习将这种方法扩展到learning orientations along with sequence order of items。
[Chen and Tian,2018]的工作提出了通过迭代地改进现有解决方案来解决VRP,简化表达和在线作业调度问题的另一种观点。 该算法没有按顺序构建解决方案,而是重写解决方案的不同部分,直到收敛为止。 状态空间表示为问题的所有解决方案的集合,而动作集则由区域及其相应的重写规则组成。 作者使用LSTM编码器(它特定于每个被涵盖的问题),并通过应用Q-Actor-Critic算法共同训练区域选择和规则选择策略。
为了学习构建完整的解决方案而不是按顺序构建,[Emami and Ranka,2018]提出了一种特定的方法。 作者设计了策略梯度方法Sinkhorn Policy Gradient(SPG),专门用于涉及置换的组合优化问题。 在这种情况下,动作空间是一组置换矩阵。 使用特殊的Sinkhorn层产生置换矩阵的连续且可区分的松弛,作者能够训练类似于深度确定性策略梯度(DDPG)的actor-critic算法[Lillicrap等,2015],并产生 最大重量匹配问题,欧几里得的TSP和整数排序问题的竞争性解决方案。
[Ma et al,2019]提出了另一种解决带有时间窗的TSP变体的方法。 主要思想是使用受[Haarnoja et al,2018]启发的分层RL框架,每层代表不同复杂度的策略:从最低层出发-使解决方案满足问题的约束;到最高层,负责为原始TSP优化问题找到解决方案。手动设计的特定于层的奖励函数和各层间共享的潜在向量h_t^(k)使不同策略层的上述行为成为可能。 原则上,潜在向量由层k的策略输出,被用作从下一层策略中采样动作的附加条件。为找到每一层的最佳策略,作者使用REINFORCE 他们有自己的 central self-critic baseline,这与self critic baseline[Rennie et al., 2017]、 rollout baseline[Kool et al., 2018]相似。
4.用于组合优化的具有自演功能的神经MCTS(Neural MCTS with Self-play)
[Laterre et al,2018]结合了可学习的政策和价值函数及MCTS和自演的组合。 为解决单人游戏形式的2D和3D装箱问题,Neural MCTS通过添加排名奖励机制来构建最佳解决方案,该机制根据近期游戏的相对表现重塑了奖励。 旨在为单个agent提供自然课程,这有点类似于两人游戏中的自然对手。
[Xu and Lieberherr,2019]以类似的方式引入了另一种方法,通过将组合优化问题转换为Zermelo Games来解决问题。 文章将具有自学习功能的神经MCTS用于学习获胜策略,该策略可以解释为原始组合问题的特定实例的解决方案。
[Huang et al,2019]通过添加称为FastColorNet的高效策略和价值函数神经网络架构,使用类似的方法来解决大型图的图着色问题。 另外,他们使用了一些技术将MCTS减少到有限的数量,以处理具有数百万个顶点的图的学习。
同样,[Abe et al,2019]提出使用图神经网络,即图形同构网络(GIN),以解决搜索树中状态表示的可变大小,并通过对值函数归一化来修改AlphaGo Zero算法 。 这些技巧被用于解决图上的最大独立集问题和其他NP-hard问题。
5.未来方向
前面的部分讨论了通过利用强化学习算法来解决canonical组合优化问题的几种方法。 这个领域正在迅速发展,我们期望出现新的算法和方法来解决当前工作的一些缺点和局限性。
a)处理大的问题实例;b)开发特定算法和训练策略以提高通用性,即在较小问题实例上进行训练并将其泛化到较大的问题。 In the same line of research,应该研究归纳为分布不同的其他问题实例。 努力设计出可以”work with various combinatorial problem classes to some specifific problems’ formulations“的算法;c)更有效的表示学习(representation learning)技术。
很久没有写有关技术的博客了,今天打算和大家分享一下我们在今年SIGGRAPH Asia上的一篇工作:Learning-based 2D Irregular Shape Packing. 我这里住要和大家分享这个项目的思考历程,具体的技术细节大家可以参考paper。

顾名思义,我们打算解决的问题,就是对任意输入的2D不规则形状,搜索得到一个紧凑的拼接方案。更加formal的来讲,就是对每个输入的不规则形状,计算一个它的位置和旋转角度,使得最后包围这些形状的矩形包围盒面积最小(Packing Efficiency最大),如上图所示。
2D不规则形状的紧密堆积问题有着广泛的应用:比如在物流领域,我们可以用这个算法在固定的package里面放入尽可能多的物体。在衣料裁制方面,我们可以用最少的布料做出尽可能多的衣服patch。在图形学方面,2D不规则形状堆积有一个很重要的应用:Atlas Generation。
我们在渲染3D模型的时候,要对模型制作纹理贴图来表示模型表面的颜色。由于模型本身是3D的,所以通常的做法是把3D模型的表面分割成多个2D Patch,然后把2D的Patch拼到一张图片里面去。

大家可以看到,当这些2D Patch被拼到一张图片里面之后,图片里面有很多地方是留白的。这些区域实际上不会再被用到,这些储存空间被浪费了。如果这些2D Patch能够做到更紧密的堆积,那么浪费的空间就会减小。我们就可以用更小的图片来储存纹理贴图,减小游戏文件的容量。
接下来我们来思考一下这个问题的难点在哪里。其实大家通过这个问题的描述就可以看出来了,这是个NP-hard问题,有着极其巨大的搜索空间: 首先做pack的时候,先去pack哪个patch?这已经就有n!的复杂度了。对于每一个要被pack的patch,它们的旋转角度和位置分别又该在哪里?这种组合的搜索空间导致这类问题基本上很难找到最优解。大部分方法都是通过heuristic的方式来找到次优的pack方案。例如:可以先把所有的patch从大到小排列,然后依次pack。每次都把patch pack到不会和已经pack好的patch发生碰撞,且当前packing efficiency最大的位置。这种greedy的方式可以生成不错的pack方案,但是依旧有提升空间。
我接手这个问题的时候,第一反应就是这是个典型的sequential decision making的问题:我们要设计一个控制策略,这个控制策略每一步从要被pack的patch里面挑一个patch出来,然后计算一个位置和旋转角度,然后把patch放到对应的地方。同学们可能会想,这不很符合reinforcement learning的setting吗?咱直接就用PPO之类的RL算法往上一套,是不是就解决了呢? 的确有一些论文尝试着把RL直接套用到这个问题上,但是我自己实现了一些结果之后,发现RL这套方法有一个根本性的问题。
我们来思考一个例子,假如我们现在要pack 5个patch,而且我们找到了一套很不错的pack方案。

现在我们继续加一个patch,这时候问题就来了。对于现在的pack方案,我们的packing efficiency非常高,但是再加上一个新的patch,就会造成packing efficiency的剧烈下降。下图是我们重新对6个patch进行pack的结果:
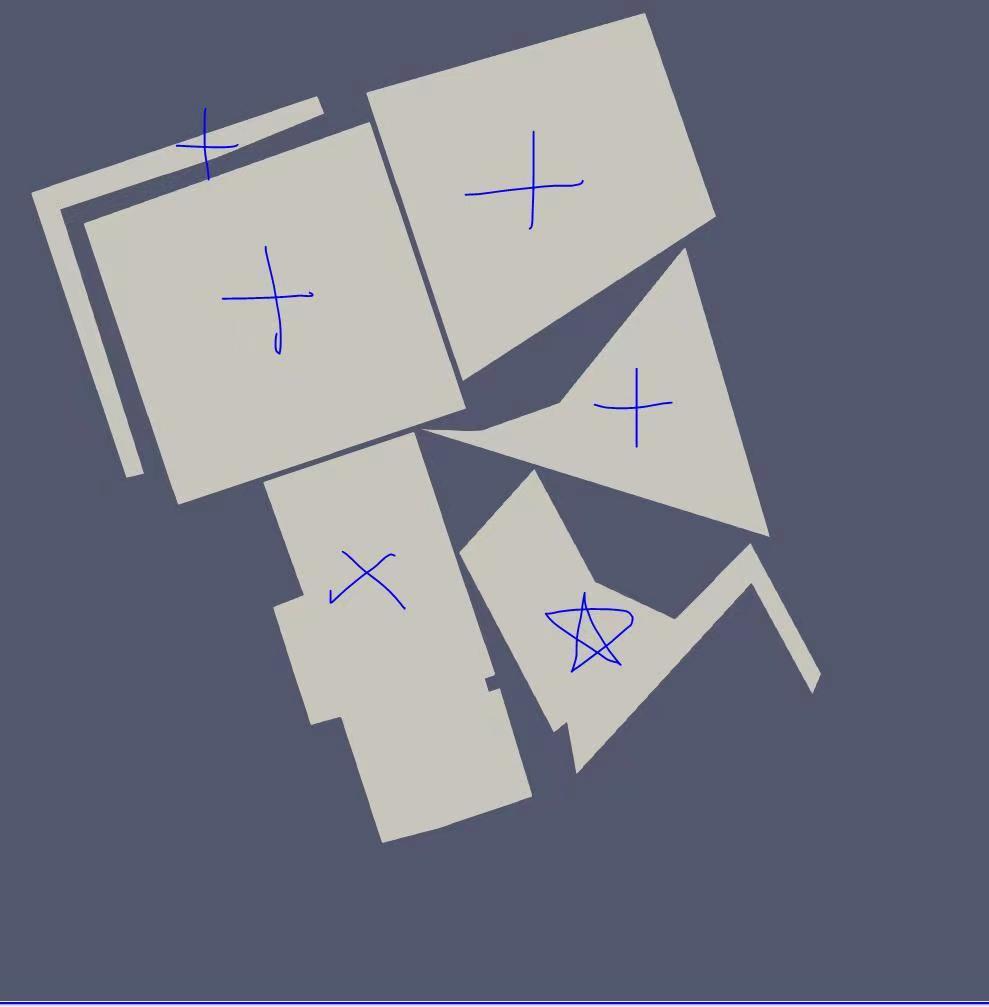
可以看到新的pack方案在很多方面和原来的5个patch的pack方案有显著不同。这个实验说明了:输入的patch的进行微小的变动,会导致packing solution上有重大的变动。换句话说,这个问题不具备单调渐优的性质,能把前K个patch pack好的方案,可能对于对前K+1个patch就是很糟糕的pack方案。但是RL一般来解决的问题都是有渐优性质的,比如我们要用RL学习一个行走控制器,机器人前K步走的稳,那么他在K+1步走的稳的概率也很大。所以这个问题(尤其是patch数目非常大的时候)不适合拿RL直接解决,除非问题规模极小,RL可以背下大部分的solution。
我当时思考到这里的时候感觉这个问题变得很困难了,没有合适的方法论可以拿来用。直到我有一天在校园里面溜达,看见了一堵工人师傅们砌的墙,突然让我有了新的思路:

我当时在想,工人师傅们是用的什么想法,可以实现这么紧密的pack方案呢。我盯着墙想了一会,觉得有一个思路是可以的:就是我们要把各种不规则的patch尽可能拼接成一个个规则,近似矩形的super patch,之后再用矩形pack的算法对这些super-patch进行拼接即可。换句话说,这个问题本来难就难在形状的不规则上,既然直接用learning输出解决方案很困难,我们不妨换个思路,用learning把这些不规则的patch转换成规则的patch,在使用一些off-the-shelf的规则形状patch pack算法解决即可。
到了这里,其实我们最重要的解决问题的思路就定下来了,接下来就是进行繁复但不复杂的系统设计了。我们的系统主要可以分成两大块:

High-level selector和Low-level packing policy。其中High-Level selector从输入的patches里面选取一组patches(一般小于等于4个),然后low-level packing policy把这组patches拼接成一个紧凑的super-patch,然后送回到原始的patches pool里面。这个过程持续进行,直到没有合适的patches可以被high-level selector选取出来。最后我们把最终的这些super-patches当作矩形进行拼接,在执行一步“压紧”操作来进一步提升pack efficiency效果。
其中Low-level packing policy就是一个用DQN训练的policy,由于每一组至多只有4个patch,所以我们之前提到的RL的问题会得到大大的减轻。对于规模如此小的问题,RL甚至可以把全部的最优解记忆下来。
而High-level selector呢,实际上也很简单,就是一个最简单的GNN。他以每个patch的几何信息作为输入,输出这些patch如果被low-level packing policy处理后的packing efficiency。我们用low-level packing policy来进行rollout产生数据训练GNN。最后在使用的时候,我们就用High-level selector选择那些预测packing efficiecny比较大的一组patches作为选择的patches即可。
这个方法的核心思路很简单直观,大家可以参考paper来了解具体的实现细节。
令我惊奇的是,这么简单的一个思路,最后的结果非常的好。我发现在和传统以及一些naive使用RL的paper做对比,我们的方法几乎是对于所有的例子都优于之前的方法。在我们的几何数据库上,我们的packing efficiency对比之前的方法有5%-10%的提升。对于一个NP-hard难的问题,这样的提升已经不算小了。下面展示一些我们的结果:


我们的方法对于上千个patch级别的问题也可以很好地处理:
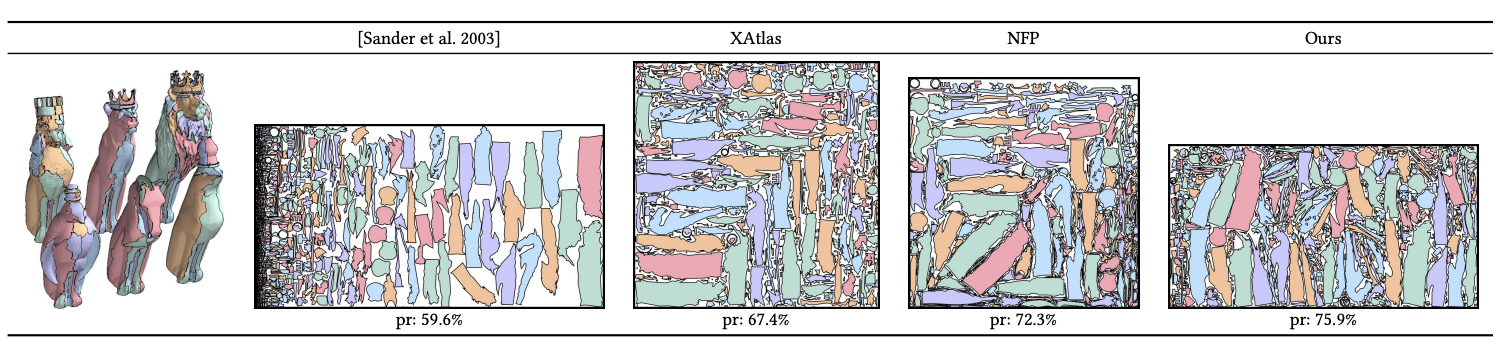
我们提出了一套系统来生成高质量的2D不规则形状堆积问题的解决方案。在这个项目里我最大的感受就是:Learning不能解决所有问题,很多时候问题的独特性质导致learning-based method不适合解决该类问题。与其用dnn直接输出最终方案,不如使用DNN来完成一些更适合DNN来处理的子问题,这样才更合适搭建一个鲁棒,高效的系统。多思考,多分析,远离无脑炼丹。与大家共勉。。。