新鲜 / 健康 / 便利 / 快速 / 放心

calcite提供了一个强大而又易于扩展的查询优化器,通过将planner中的Rule反复应用于Relnode来优化,通过Cost Model指导该过程,尝试生成与原始输入有相同语义但成本较低的执行/逻辑计划。
本文的目的:
为了防止内容膨胀,本文尽量不大段引入源码,引用部分尽量选择段落文字较小的核心逻辑;每章的结尾会有这段内容的小结,想忽略细节,快速了解机制的朋友可以直接阅读这部分。以下内容基于Calcite 1.35的实现。
以一个简单的Sql为例子
select * from "order" a
join
"item" b
on "a"."oItemId"="b"."iItemId"
where a.oOrderDate > '2023-08-22'RelNode树如下
LogicalProject(oOrderId=[$0], oItemId=[$1], oShopId=[$2], oPrice=[$3], oOrderDate=[$4], iItemId=[$5], iItemName=[$6], iItemType=[$7], iCategoryId=[$8])
LogicalJoin(condition=[=($1, $5)], joinType=[inner])
LiteLogicalBaseScan(table=[[order]])
LiteLogicalBaseScan(table=[[item]])每一行是一个Relnode
经过一个自定义的Logical Trait 转换后
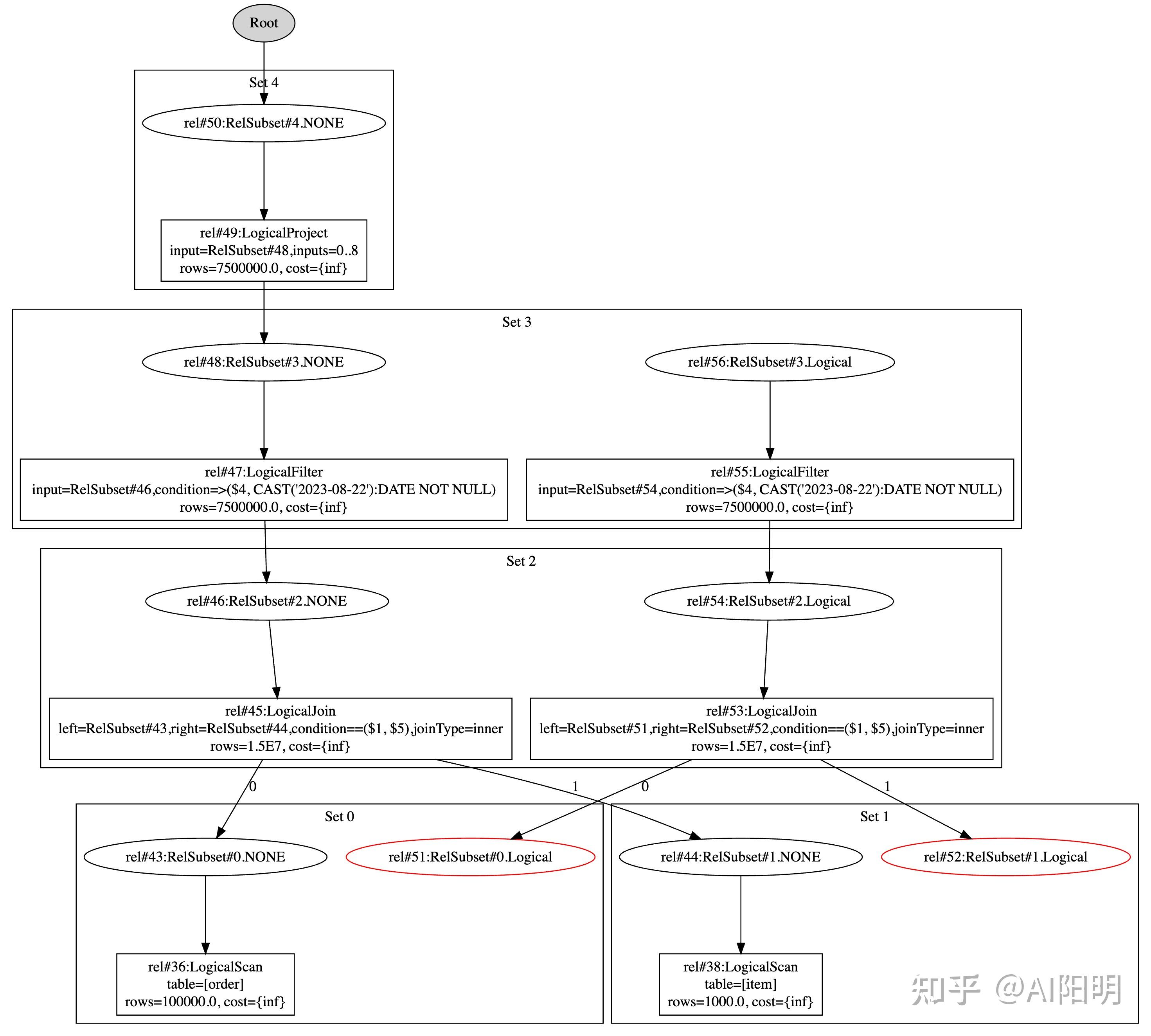
如上图,一个set内有多个RelSubset,每个subset有自己的trait定义,比如一个是None,一个是Logical
RelsubSet包含对应物理属性的relNode,通过这张图, 可以简单理解下这几个概念。
关系代数的逻辑最终被 RelNode树来表示,其中Relset代表语义相同(可以有不同的特性),RelSubSet代表特性相同。相同逻辑下,有不同逻辑路径和不同的物理执行方法,优化器就是在这个由包含关系和等价关系组成的树中,寻找最优执行计划的
Apache Calcite 中的 VolcanoPlanner 是对 Volcano/Cascades 优化器的实现,我们会从以下几个角度展开,来一窥优化器运转的全貌
上面提到,优化器的主要目前是对于输入的RelNode求解出最优的输出RelNode
那么从使用层面,主流程主要包括三个部分
优化器的基本接口是RelOptPlanner,其中以下方法
都可以视为为优化器工作提前做的准备,用户可以根据自己的需要设置 特性、待执行的规则、物化视图或lattice用于查询改写、监听器用于跟踪流程等等
setRoot实质上就是将要处理的Relnode输入
这么说起来可能觉得这里很简单,但却不是一个单纯的设置动作,它会涉及到优化器中的一个重要动作--Register
Register动作的目的,是在planner里面注册节点,并生成或归因到Relset和RelsubSet
注册的过程非常复杂,但梳理起来大致包含以下几个步骤:
后面专门会细拆这个注册的过程
通过上面的步骤,我们可以获得一个初始输入和组织好的RelSet + RelSubSet + Relnode的树,在这一步,规则将在ruleDriver的驱动下执行,并不断产生RelNode、RelSubSet和RelSet,当可执行的规则已经执行完毕,Relsubset均已经计算出BestCost。最后通过buildCheapestPlan获取最优节点则会比较简单,直接从root向下寻找每个等价集合的最优节点,连接起来即可。下图是一个优化器处理RelNode例子,其中蓝色线部分为选出的最优计划。

因此一个最简化的使用Volcano优化器的非典型性代码如下
VolcanoPlanner planner = rel.getCluster().getPlanner();
planner.addRelTraitDef(ConventionTraitDef.INSTANCE);
planner.addRelTraitDef(RelCollationTraitDef.INSTANCE);
for (RelOptMaterialization materialization : materializations) {
planner.addMaterialization(materialization);
}
for (RelOptLattice lattice : lattices) {
planner.addLattice(lattice);
}
for (RelOptRule rule : ruleSet) {
planner.addRule(rule);
}
if (!rel.getTraitSet().equals(requiredOutputTraits)) {
rel = planner.changeTraits(rel, requiredOutputTraits);
}
planner.setRoot(rel);
planner.findBestExp()概括来说,第一步提供了优化执行的上下文所需的各种素材,第二步设置根节点,并开始第一轮注册,最重要的第三步完成规则的驱动执行、子集的代价计算及最终方案的选出。在这个流程中,有很多组件需要配合来运作,后面几部分会结合核心组件来从细节上拆解优化器执行流程。
下面我们开始分块详解每部分的重要流程和逻辑,梳理其间联系
Listener是个很重要的辅助机制,能够在优化器的各个阶段提供回调。
暂且不提功能,最简单的场景是使得核心流程可以落到日志中或者可视化,目前已经比较常见的事件回调如下
当检测到等价或者断言等价后通知
将被调用,有两次:一次在规则被调用之前,一次在规则被调用之后。请注意,事件的rel属性始终是旧的表达式
rule已成功应用于特定的关系表达式,从而产生了一个新的等效表达式(除非新表达式与现有表达式相同,否则还将调用relEquivalenceFound)。该规则将被调用两次:一次在注册新rel之前,一次在之后。请注意,事件的rel属性始终是新的表达式;要获取旧的表达式,请使用event.getRuleCall().rels[0]
relnode被丢弃
已被选作查询计划的最终实现的一部分,比如Hep的buildFinalPlan,Volcano的buildCheapestPlan等
这些核心事件的监听器为我们能track整个优化过程提供了很好的帮助
/**
* Gets the rule queue.
*/
RuleQueue getRuleQueue();
/**
* Applies rules.
*/
void drive();
/**
* Callback when new RelNodes are added into RelSet.
*
* @param rel the new RelNode
* @param subset subset to add
*/
void onProduce(RelNode rel, RelSubset subset);
/**
* Callback when RelSets are merged.
*
* @param set the merged result set
*/
void onSetMerged(RelSet set);规则执行的驱动器,包含了基本的rule队列操作,实现不同的drive机制来apply rule,提供一些回调等。
目前calcite实现了TopDown(TopDownRuleDriver)和BottomUp(IterativeRuleDriver)两种ruleDriver,本文以IterativeRuleDriver为主
优化器执行的重要载体,VolcanoRuleCall有两个重要方法: 匹配(onMatch)和转换(TransformTo)
注意:这个方法不是父类中的
Step 1: 判断rule是否被排除,过滤条件是一个正则或者hint的策略
Step 2: rels是一个call的多个operand,判断是否有任意一个rel需要跳过,比如prune或者已经有等价set
for (int i=0; i < rels.length; i++){
RelNode rel=rels[i];
RelSubset subset=volcanoPlanner.getSubset(rel);
if (subset==null){
LOGGER.debug(
"Rule[{}]not fired because operand #{}({}) has no subset",
getRule(), i, rel);
return;
}
if ((subset.set.equivalentSet !=null)
// When rename RelNode via VolcanoPlanner#rename(RelNode rel),
// we may remove rel from its subset: "subset.set.rels.remove(rel)".
// Skip rule match when the rel has been removed from set.
|| (subset !=rel && !subset.contains(rel))){
LOGGER.debug(
"Rule[{}]not fired because operand #{}({}) belongs to obsolete set",
getRule(), i, rel);
return;
}
}Step 3: 调用rule的onmatch
/**
* Registers that a rule has produced an equivalent relational expression,
* but no other equivalences.
*
* <p>The hints are copied with filter strategies from
* the root relational expression of the rule call(<code>this.rels[0]</code>)
* to the new relational expression(<code>rel</code>).
*
* @param rel Relational expression equivalent to the root relational
* expression of the rule call,{@code call.rels(0)}
*/
public final void transformTo(RelNode rel){
transformTo(rel, ImmutableMap.of());
}从注释可以看出,这个转换动作完成了等价关系代数的生成和注册
这里我们主要看下VolcanoRuleCall的实现
// Step 1
rel=handler.propagate(rels[0], rel);
// Step 2
if (this.getRule() instanceof SubstitutionRule
&& ((SubstitutionRule) getRule()).autoPruneOld()){
volcanoPlanner.prune(rels[0]);
}
// Step 3
// Registering the root relational expression implicitly registers
// its descendants. Register any explicit equivalences first, so we
// don't register twice and cause churn.
for (Map.Entry<RelNode, RelNode> entry : equiv.entrySet()){
volcanoPlanner.ensureRegistered(
entry.getKey(), entry.getValue());
}
RelSubset subset=volcanoPlanner.ensureRegistered(rel, rels[0]);上面贴出了transformTo的核心逻辑,梳理下来包括以下过程
Step 1 : 将hint从root 的relnode 传播到新生成的等价relnode
Step 2 : 对于确定性优化的裁剪,避免在优化器的搜索空间引入过多的无意义节点
SubstitutionRule 实现这个接口表明 新的RelNode通常比旧的更好。所有的替换规则将首先执行,直到完成,如果该规则设置了autoPruneOld,那么老的relnode会直接prune掉
autoPrune的默认值是false,只有少量规则重写为true,比如ProjectRemove,但是仍然有很多Rule直接在规则中显示地裁剪了call.getPlanner().prune(xxx),为什么会有这个现象,因为SubstitutionRule的提交时间比较新,2020年,之前的规则已经有prune的逻辑
Step 3: ensureRegistered,确保注册等价类
过程中还伴随着各种事件通知,即使用到Listen来做一些日志记录等
Convention也是继承自Trait,常见的Convention有NONE,BindableConvention,EnumerableConvention,JdbcConvention,在虚拟化引擎中也可以自定义Convention来表示不是实际物理执行的约定
Trait目前常见的是排序RelCollation和分布RelDistribution
为什么需要转成带Convention的算子,从业务意义上来说,代表这个算子到了执行层面,从逻辑意义上来说,由于noneConventionHasInfiniteCost的开关,没有Convention的算子,代价为Infinite
Convention中还有一个方法:enforce
用来对齐relnode 的traitset,比如EnumerableConvertion的实现

AbstractConverter
AbstractConverter类是一个抽象的RelNode转换器,用于将RelNode转换为任意给定的输出规范。
与大多数RelOptRuleCall的Converter不同,AbstractConverter始终是抽象的。您通常在需要立即进行关系表达式转换的情况下创建一个AbstractConverter。随后,规则将会将其转换为可实现的关系表达式。
如果无法立即满足抽象转换器的要求(因为源子集是抽象的),则会标记该集合,以便在将非抽象的RelNode添加到集合中时立即扩展该转换器。
ExpandConversionRule是一个将AbstractConverter转换为从源关系到目标特征的转换链的规则。
它会生成一个最小的转换链,因为之前已经构建了转换图的传递闭包,因此我们可以选择最短的链路。
与AbstractConverter不同,这些转换器能够确保能够将任何符合其调用约定的关系转换为目标特征。此外,由于这些转换器在转换过程中会引入其他调用约定的子集,因此这些子集可能会生成不适用于一般情况的更高效的转换结果。
这段代码的目的是定义抽象转换器和相应的转换规则,用于在查询计划优化过程中进行关系转换。AbstractConverter是一个抽象的关系节点转换器,用于立即将RelNode转换为指定的输出规范。ExpandConversionRule是一个规则,用于将AbstractConverter转换为能够处理特定特征集的转换链。它通过计算最短的转换链来生成最佳的转换结果。
优化器操作对象的主体是RelNode/RelSubset/Relset, 规则调用的主体是RuleCall,特性的主体是Convention和Trait,再辅助以一些流程上的组件,构成了优化器运行的基本框架。
这一部分涉及到具体代码实现的逻辑,前面主流程里提到,实际优化器实际运作的入口是setRoot,这里就包含了两个重要的方法: ensureRootConverters 和 registerImpl
public void setRoot(RelNode rel) {
this.root = registerImpl(rel, null);
if (this.originalRoot == null) {
this.originalRoot = rel;
}
rootConvention = this.root.getConvention();
ensureRootConverters();
}确保root的subset包含其等价集中的所有其他子集的converter,这是planner中唯一需要显式转换器的地方,其他地方都有consumer去要求做一个convention动作,而root没有consumer
注册一个新的relnode并排队规则匹配。如果传入的set参数不为null,则将relnode设置为该等价集的一部分。
如果已经注册了相同的relnode,则不需要再注册该表达式,也不应该排队规则匹配,最后返回一个等价集合RelSubset
当注册RelNodes的树时,有时节点的成本会改善,但子集却不知道。可能会出现一个子集,其中单个关系的成本是99,但它认为自己的最佳成本是100。我们认为这是因为与父节点的反向链接没有建立。因此,给子集另一次机会来计算出自己的成本
public RelSubset ensureRegistered(RelNode rel, @Nullable RelNode equivRel){
RelSubset result;
final RelSubset subset=getSubset(rel);
if (subset !=null){
if (equivRel !=null){
final RelSubset equivSubset=getSubsetNonNull(equivRel);
if (subset.set !=equivSubset.set){
merge(equivSubset.set, subset.set);
}
}
result=canonize(subset);
}else{
result=register(rel, equivRel);
}
// Checking if tree is valid considerably slows down planning
// Only doing it if logger level is debug or finer
if (LOGGER.isDebugEnabled()){
assert isValid(Litmus.THROW);
}
return result;
}其中核心的动作是做两个Relset的merge
基于输入的关系节点(rel),初始化一个优先级队列(propagateHeap)和一个关系节点到成本的映射(propagateRels)。
该函数通过传播cost改进来优化查询计划。它使用优先级队列和成本映射来管理节点的传播顺序,并根据成本的变化更新subset的最佳成本和最佳关系节点,以及相关节点的元数据缓存。通过传播成本的改进,可以在计划优化过程中逐步改进计划的成本估算,从而得到更优化的查询执行计划。
到这一步subset里的代价计算已经结束了,实际上是在等价类生成时已经计算好了,直接从root的subset开始,向下找到所有节点的best,每个节点处理完之后标记为已访问。
void fireRules(RelNode rel){
for (RelOptRuleOperand operand : classOperands.get(rel.getClass())){
if (operand.matches(rel)){
final VolcanoRuleCall ruleCall;
ruleCall=new DeferringRuleCall(this, operand);
ruleCall.match(rel);
}
}
}DeferringRuleCall 延迟调用,不同与 RelOptRuleCall直接调用,这里不直接执行,而是放到queue中
主要靠 CheapestPlanReplacer来实现,求解root的relsubset的最优计划
buildCheapestPlan之上的几个步骤实际上是在不断交织运行的,也是最复杂的一段逻辑,但是对于使用者来说,这一部分需要修改做二次开发的场景不多,理解整体的功能链路还是比较清晰的
前面提到,我们认为Calcite 的 Volcanno优化器是一个 强大 并且 扩展性强 的优化器
实现层面尤其是在加入了TopDownRuleDriver之后,基本已经是Cascades机制的优化器,搜索空间的组织、规则执行的合理性、代价计算和传播、分支裁剪等保障了优化器在优化时间和优化效果上有一个比较好的预期
2. 扩展性强:
除了前面提到的add/remove系列方法外,还有一些非常好扩展的点
优化器往往是数据库引擎非常核心的一部分,然后这套机制其实不仅限于生成执行计划,比如对于虚拟化引擎,在优化器层可以做到基于引擎特色的规则编排和代价评估来决定实际连接引擎执行的方式,同时也可以作为MVS(物化视图选择)话题的一个搜索和执行评估框架。
最后,最优计划不是追求一般意义的完全最优计划,计划实际效果和planning时间的trade off也同样重要。